8 Useful Python Libraries for SEO & How To Use Them
Python libraries are a fun and accessible way to get started with learning and using Python for SEO.
A Python library is a collection of useful functions and code that allow you to complete a number of tasks without needing to write the code from scratch.
There are over 100,000 libraries available to use in Python, which can be used for functions from data analysis to creating video games.
In this article, you’ll find several different libraries I have used for completing SEO projects and tasks. All of them are beginner-friendly and you’ll find plenty of documentation and resources to help you get started.
Why Are Python Libraries Useful for SEO?
Each Python library contains functions and variables of all types (arrays, dictionaries, objects, etc.) which can be used to perform different tasks.
Advertisement
Continue Reading Below
For SEO, for example, they can be used to automate certain things, predict outcomes, and provide intelligent insights.
It is possible to work with just vanilla Python, but libraries can be used to make tasks much easier and quicker to write and complete.
Python Libraries for SEO Tasks
There are a number of useful Python libraries for SEO tasks including data analysis, web scraping, and visualizing insights.
This is not an exhaustive list, but these are the libraries I find myself using the most for SEO purposes.
Pandas
Pandas is a Python library used for working with table data. It allows for high-level data manipulation where the key data structure is a DataFrame.
DataFrames are similar to Excel spreadsheets, however, they are not limited to row and byte limits and are also much faster and more efficient.
The best way to get started with Pandas is to take a simple CSV of data (a crawl of your website, for example) and save this within Python as a DataFrame.
Advertisement
Continue Reading Below
Once you have this stored in Python, you can perform a number of different analysis tasks including aggregating, pivoting, and cleaning data.
For example, if I have a complete crawl of my website and want to extract only those pages that are indexable, I will use a built-in Pandas function to include only those URLs in my DataFrame.
import pandas as pd
df = pd.read_csv('/Users/rutheverett/Documents/Folder/file_name.csv')
df.head
indexable = df[(df.indexable == True)]
indexable
Requests
The next library is called Requests and is used to make HTTP requests in Python.
Requests uses different request methods such as GET and POST to make a request, with the results being stored in Python.
One example of this in action is a simple GET request of URL, this will print out the status code of a page:
import requests
response = requests.get('https://www.deepcrawl.com') print(response)
You can then use this result to create a decision-making function, where a 200 status code means the page is available but a 404 means the page is not found.
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
You can also use different requests such as headers, which display useful information about the page like the content type or how long it took to cache the response.
headers = response.headers print(headers) response.headers['Content-Type']
There is also the ability to simulate a specific user agent, such as Googlebot, in order to extract the response this specific bot will see when crawling the page.
headers = 'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' ua_response = requests.get('https://www.deepcrawl.com/', headers=headers) print(ua_response)

Beautiful Soup
Beautiful Soup is a library used to extract data from HTML and XML files.
Fun fact: The BeautifulSoup library was actually named after the poem from Alice’s Adventures in Wonderland by Lewis Carroll.
Advertisement
Continue Reading Below
As a library, BeautifulSoup is used to make sense of web files and is most often used for web scraping, as it can transform an HTML document into different Python objects.
For example, you can take a URL and use Beautiful Soup together with the Requests library to extract the title of the page.
from bs4 import BeautifulSoup import requests url="https://www.deepcrawl.com" req = requests.get(url) soup = BeautifulSoup(req.text, "html.parser") title = soup.title print(title)

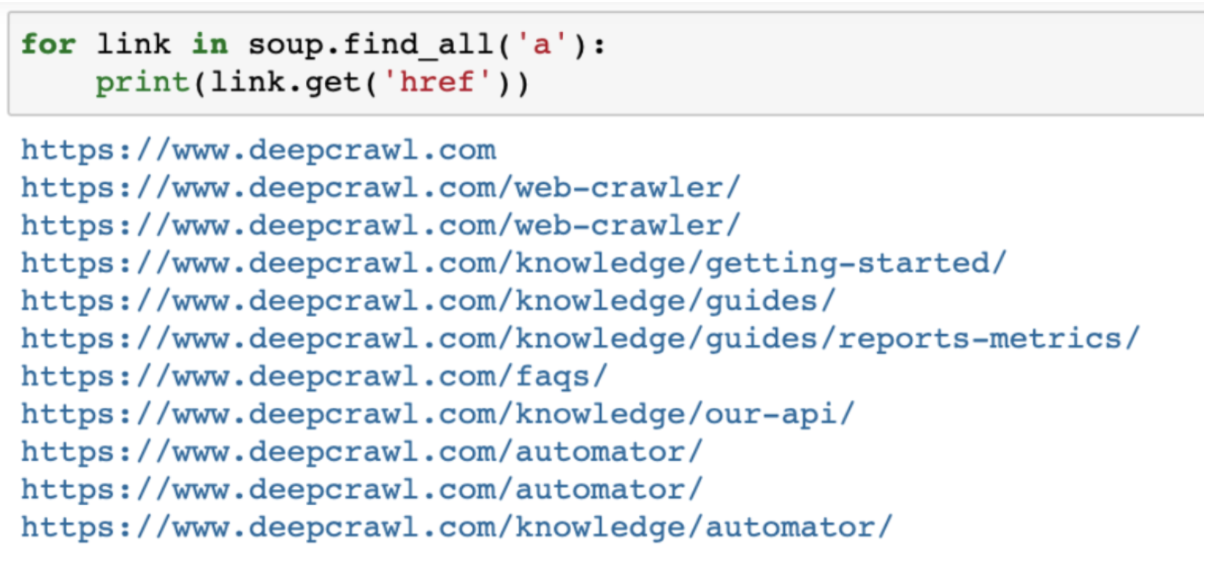
Additionally, using the find_all method, BeautifulSoup enables you to extract certain elements from a page, such as all a href links on the page:
Advertisement
Continue Reading Below
url="https://www.deepcrawl.com/knowledge/technical-seo-library/"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
Putting Them Together
These three libraries can also be used together, with Requests used to make the HTTP request to the page we would like to use BeautifulSoup to extract information from.
We can then transform that raw data into a Pandas DataFrame to perform further analysis.
URL = 'https://www.deepcrawl.com/blog/'
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
links = soup.find_all('a')
df = pd.DataFrame('links':links)
df
Matplotlib and Seaborn
Matplotlib and Seaborn are two Python libraries used for creating visualizations.
Matplotlib allows you to create a number of different data visualizations such as bar charts, line graphs, histograms, and even heatmaps.
Advertisement
Continue Reading Below
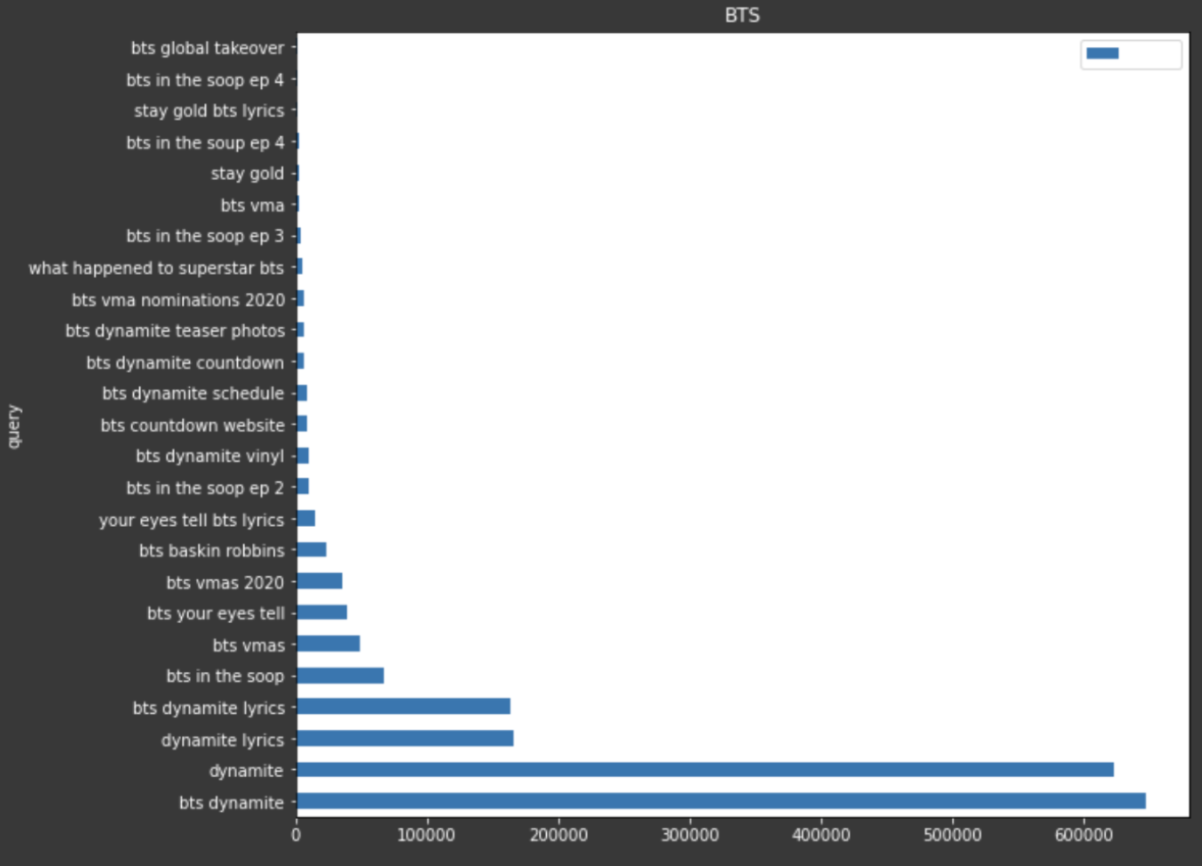
For example, if I wanted to take some Google Trends data to display the queries with the most popularity over a period of 30 days, I could create a bar chart in Matplotlib to visualize all of these.
Seaborn, which is built upon Matplotlib, provides even more visualization patterns such as scatterplots, box plots, and violin plots in addition to line and bar graphs.
It differs slightly from Matplotlib as it uses fewer syntax and has built-in default themes.
Advertisement
Continue Reading Below
One way I’ve used Seaborn is to create line graphs in order to visualize log file hits to certain segments of a website over time.
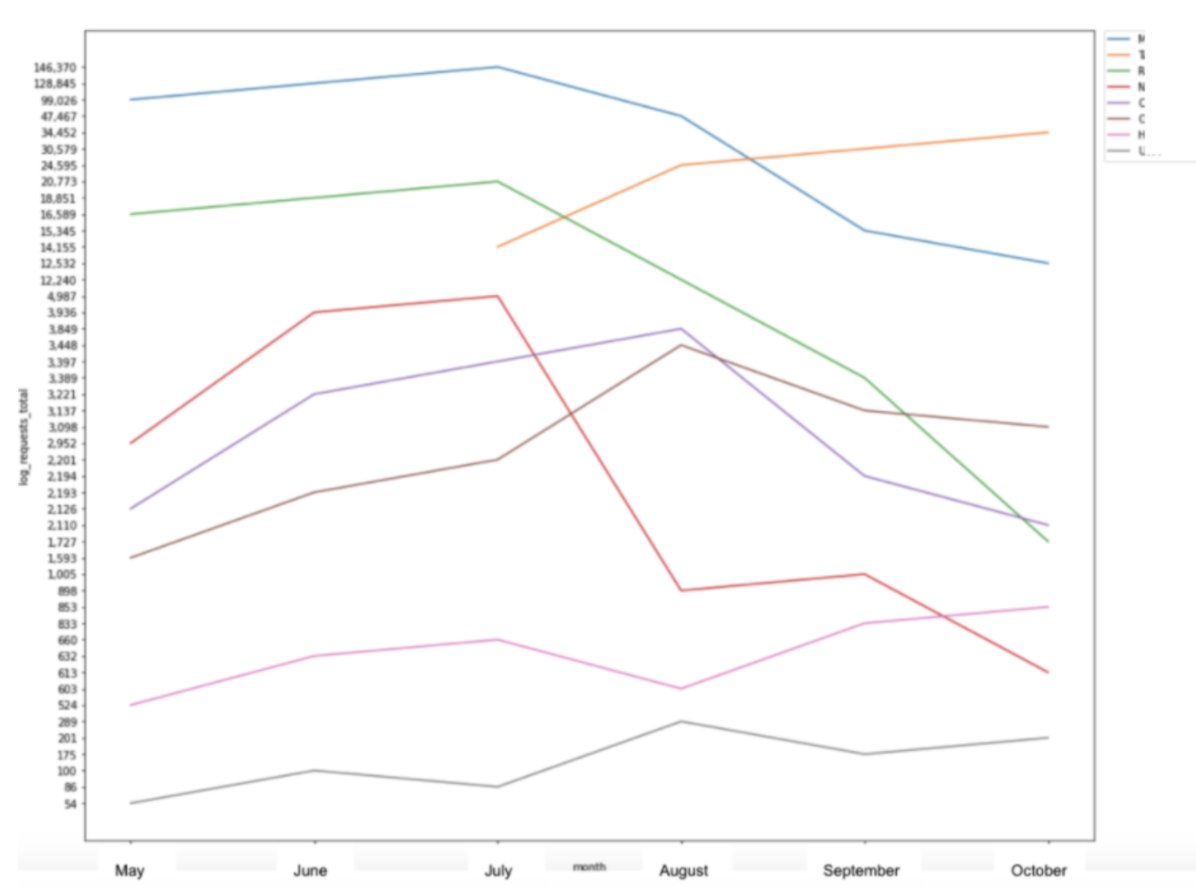
sns.lineplot(x = "month", y = "log_requests_total", hue="category", data=pivot_status) plt.show()
This particular example takes data from a pivot table, which I was able to create in Python using the Pandas library, and is another way these libraries work together to create an easy-to-understand picture from the data.
Advertools
Advertools is a library created by Elias Dabbas that can be used to help manage, understand, and make decisions based on the data we have as SEO professionals and digital marketers.
Advertisement
Continue Reading Below
Sitemap Analysis
This library allows you to perform a number of different tasks such as downloading, parsing, and analyzing XML Sitemaps to extract patterns or analyze how often content is added or changed.
Robots.txt Analysis
Another interesting thing you can do with this library is to use a function to extract a website’s robots.txt into a DataFrame, in order to easily understand and analyze the rules set.
You can also run a test within the library in order to check whether a particular user-agent is able to fetch certain URLs or folder paths.
URL Analysis
Advertools also enables you to parse and analyze URLs in order to extract information and better understand analytics, SERP, and crawl data for certain sets of URLs.
You can also split URLs using the library to determine things such as the HTTP scheme being used, the main path, additional parameters, and query strings.
Selenium
Selenium is a Python library that is generally used for automation purposes. The most common use case is testing web applications.
Advertisement
Continue Reading Below
One popular example of Selenium automating a flow is a script that opens a browser and performs a number of different steps in a defined sequence such as filling in forms or clicking certain buttons.
Selenium employs the same principle as is used in the Requests library that we covered earlier.
However, it will not only send the request and wait for the response but also render the webpage that is being requested.
To get started with Selenium, you will need a WebDriver in order to make the interactions with the browser.
Each browser has its own WebDriver; Chrome has ChromeDriver and Firefox has GeckoDriver, for example.
These are easy to download and set-up with your Python code. Here is a useful article explaining the setup process, with an example project.
Scrapy
The final library I wanted to cover in this article is Scrapy.
While we can use the Requests module to crawl and extract internal data from a webpage, in order to pass that data and extract useful insights we also need to combine it with BeautifulSoup.
Advertisement
Continue Reading Below
Scrapy essentially allows you to do both of these in one library.
Scrapy is also considerably faster and more powerful, completes requests to crawl, extracts and parses data in a set sequence, and allows you to shield the data.
Within Scrapy, you can define a number of instructions such as the name of the domain you would like to crawl, the start URL, and certain page folders the spider is allowed or not allowed to crawl.
Scrapy can be used to extract all of the links on a certain page and store them in an output file, for example.
class SuperSpider(CrawlSpider):
name="extractor"
allowed_domains = ['www.deepcrawl.com']
start_urls = ['https://www.deepcrawl.com/knowledge/technical-seo-library/']
base_url="https://www.deepcrawl.com"
def parse(self, response):
for link in response.xpath('//div/p/a'):
yield
"link": self.base_url + link.xpath('.//@href').get()
You can take this one step further and follow the links found on a webpage to extract information from all the pages which are being linked to from the start URL, kind of like a small-scale replication of Google finding and following links on a page.
from scrapy.spiders import CrawlSpider, Rule
class SuperSpider(CrawlSpider):
name="follower"
allowed_domains = ['en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Web_scraping']
base_url="https://en.wikipedia.org"
custom_settings =
'DEPTH_LIMIT': 1
def parse(self, response):
for next_page in response.xpath('.//div/p/a'):
yield response.follow(next_page, self.parse)
for quote in response.xpath('.//h1/text()'):
yield 'quote': quote.extract()
Learn more about these projects, among other example projects, here.
Final Thoughts
As Hamlet Batista always said, “the best way to learn is by doing.”
Advertisement
Continue Reading Below
I hope that discovering some of the libraries available has inspired you to get started with learning Python, or to deepen your knowledge.
Python Contributions from the SEO Industry
Hamlet also loved sharing resources and projects from those in the Python SEO community. To honor his passion for encouraging others, I wanted to share some of the amazing things I have seen from the community.
As a wonderful tribute to Hamlet and the SEO Python community he helped to cultivate, Charly Wargnier has created SEO Pythonistas to collect contributions of the amazing Python projects those in the SEO community have created.
Hamlet’s priceless contributions to the SEO Community are featured.
Moshe Ma-yafit created a super cool script for log file analysis, and in this post explains how the script works. The visualizations it is able to display including Google Bot Hits By Device, Daily Hits by Response Code, Response Code % Total, and more.
Koray Tuğberk GÜBÜR is currently working on a Sitemap Health Checker. He also hosted a RankSense webinar with Elias Dabbas where he shared a script that records SERPs and Analyses Algorithms.
Advertisement
Continue Reading Below
It essentially records SERPs with regular time differences, and you can crawl all the landing pages, blend data and create some correlations.
John McAlpin wrote an article detailing how you can use Python and Data Studio to spy on your competitors.
JC Chouinard wrote a complete guide to using the Reddit API. With this, you can perform things such as extracting data from Reddit and posting to a Subreddit.
Rob May is working on a new GSC analysis tool and building a few new domain/real sites in Wix to measure against its higher-end WordPress competitor while documenting it.
Masaki Okazawa also shared a script that analyzes Google Search Console Data with Python.
🎉 Happy #RSTwittorial Thursday with @saksters 🥳
Analyzing Google Search Console Data with #Python 🐍🔥
Here’s the output 👇 pic.twitter.com/9l5Xc6UsmT
— RankSense (@RankSense) February 25, 2021
More Resources:
Advertisement
Continue Reading Below
Image Credits
All screenshots taken by author, March 2021






